
These values used to coincide but now the spread between them is widening which suggests that younger people may have an advantage when it comes to getting hired. They're less picky and more willing to accept anything that has some dollar signs attached to it versus the older and more demanding unemployed member of society. In the graph below the blue line represents those aged 25-34 that are unemployed and the black line is for 20-24 age range.

Check out the below graph which shows the unemployment rate for those over 25 with a bachelors degree, those without one and those that didn't graduate high school. Getting a bachelors is not a sufficient condition for employment but as the graph below shows, you do have greater job security.
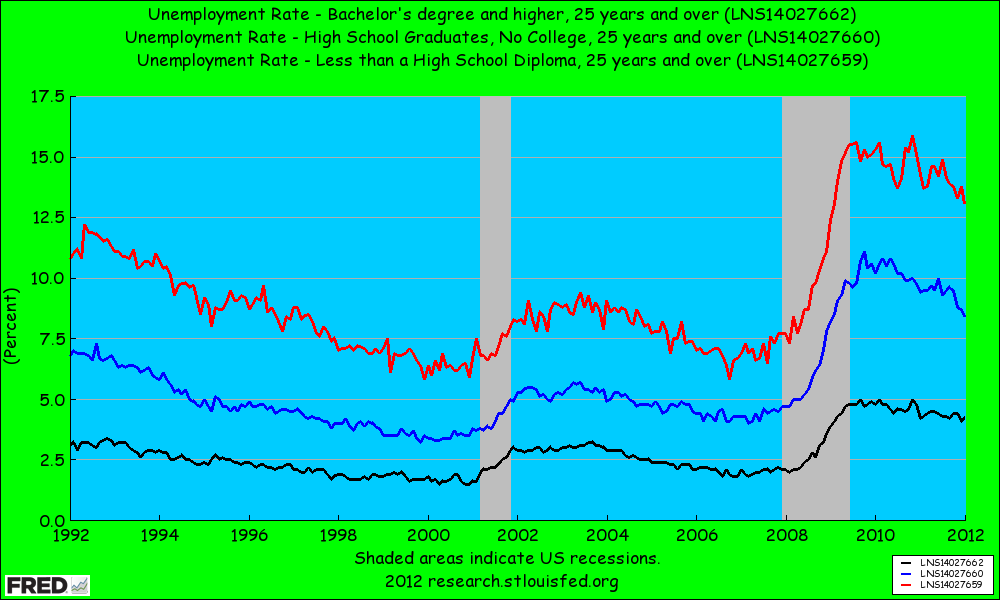

The unemployment rate for those who graduated high school is currently 4% higher than those that got their bachelors. Lesson of the day: Read more books and get some education. I got to keep dancin' and so should you!
Steven J.











